2023-02-21 9:32
Video 44

左侧abr会弹出ldp标签,将bgp标签swap为abr2(左侧第二台)分配的bgp标签+如果两台r之间还存在其他设备,就再压入ldp标签-用于穿越本端as。bgp标签用在区域边界设备上。
标签报文到达末段区域后,在这台abr上会把bgp标签置换为ldp标签,两层标签发出去(cisco默认行为,也可以选择再封装两层标签)

sr的替代关系
mpls本质来说是标签转发功能,而不是一种协议,如果不开启mpls,设备就仅支持ip转发。光开启标签转发还不够,还需要生成lsp-是基于路由之上的service。
分配标签的协议:1.ldp/tdp(cisco)只能为igp,direct,static分配标签。2.bgp-只能为bgp路由分配标签,在seamless和option c场景中应用。3.mpbgp,只能为vpn路由分配标签。4.rsvp-te
rsvp本质属于qos。qos针流量转发有三种模型,fifo-先进先出,集成服务模型(用到rsvp)和差分服务模型(PHB)。
rsvp:指从源到目的,提前为流量预留带宽。问题在于这个带宽是预留的,即是你的流量没有,也不能给别的流量用。需要提前预留带宽
phb:每一跳行为,需要在经过的每一台r上都是设置phb,通过phb就可针对流量进行限速,好处是不需要提前预留带宽,缺点在于需要在每一台设备上都需要为流量进行配置。流量在经过每一条r时,都需要做流量带宽的保证和按优先级转发。每一台设备上都需要配置。phb只有传输时会占带宽,不传时带宽资源会释放。
te用到的底层协议也是rsvp,只不过是增强版te:流量工程。
在te中需要做两点:1.为流量预留带宽-使用rsvp协议,从源到目的来预留;2.te是基于标签转发的,但其不可能使用ldp来分发标签(参照ldp能够分发标签的范围),标签就由rsvp来发。
te中 rsvp的两个作用:1.提前预留带宽。2.给te隧道分配标签,建立一条源到目的的te的 lsp。如果后续流量通过该tunnel转发,流量都会被打上te的标签。te也是mpls技术的延伸。
mpls的基础协议,ldp和mpls-te,都可以作为承载上层业务的底层lsp

在seamless场景中,可以使用mpls-te来替换ldp,从源到目的建立一条端到端的mpls-te lsp。ldp和mpls-te都是用来构建承载上层业务的底层的lsp。sr是用来替代ldp和mpls-te,也是工作在底层的,sr的lsp建立完成后,就可以通过sr lsp来承载上层业务(如l2vpn/l3vpn)
Mpls-te并不是一种qos,只是用到qos中的rsvp来提前为te的隧道预留带宽,是一种来提高服务质量的工具

网络工程:设计者对网络的部署
流量工程:设计者对流量规划的引导。人为指定流量的转发路径。
通过pbr可以实现指定路径转发,pbr绑定acl,通过acl去match 流量,然后通过pbr的方式指导流量转发。使用pbr的问题:如果策略条目过多,会导致控制层面压力过大-设备性能下降,因为pbr的分析工作都是需要控制层面实现的,控制层面分析后下发到转发层面,板卡在收到流量后能根据下发的表项直接转发。同时需要在每一台r上都部署pbr(包括中间的),导致工作量过大。
通过mpls-te来指导流量转发,在mpls-te里为流量指定转发路径,如果流量通过te的tunnel转发的时候,就会按照这个路径转发,称为流量工程。

Mpls-te是实现流量工程的工具
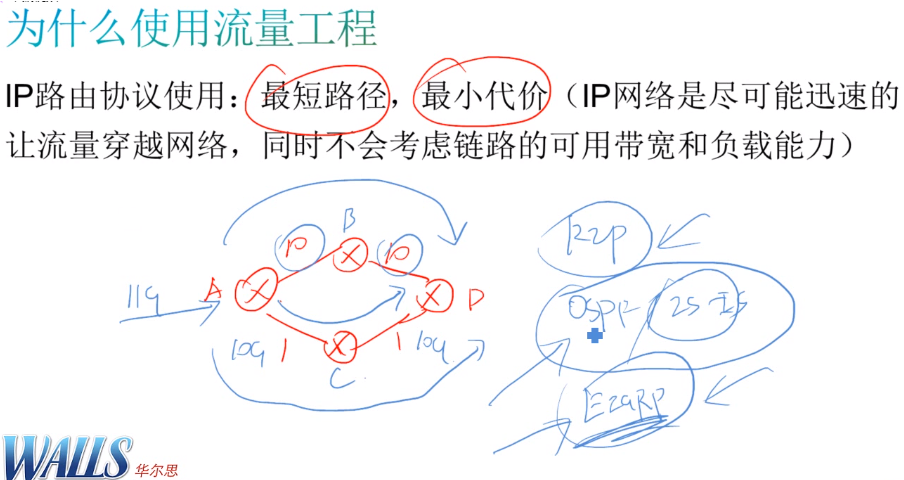
igp选路只会看cost,而不会看链路的拥塞程度。像上图蓝色部分流量路径,拥塞时走上下负载,igp实现不了。igp中:rip是看的跳数,isis和ospf是看的接口带宽来计算的cost值。eigrp在设计之初就考虑了链路拥塞的问题,通过5元组的公式来计算metric。如果链路流量过大,会导致延时增大,最终导致metric增大

te可以动态计算转发路径的,要求可以实时收到链路的带宽。ex:链路只用了100m,te选择该链路。当这条链路使用10g,te就将流量动态切换到上面的链路上联,从而避免大量的丢包和延时。




Ip-frr是用于快速切换的,跟te没关系

通过调整cost影响igp选路,是不能区分流量的 (比如voice流量和video流量),所有流量都会切到相同的转发路径上。
在如图r3连r1 的if上配置pbr,match流量指定不同的转发路径,能实现需求,但消耗资源

显示路径:我提前规划好的,你要按我的路径来转发

当前很多isp也会大面积部署mpls-te,但看中的不是预留带宽和指定转发路径,更看重的是te-frr功能,保护重要流量,故障切换实现小于50ms。在没有ip-frr之前只能部署te-frr。isp针对重要流量,不仅可以限制带宽,预留带宽还可以提供failover保障-当出现链路或节点故障,可以保证重要流量的快速切换。而后来出现ip-frr之后,可以针对每一条前缀提供备份路径,te部署的少了。
Ip frr配置:1.静态;2.动态:lfa、remote lfa、ti-lfa。lfa和remote-lfa用于igp+ldp的场景,ti-lfa用在sr场景中。ti:拓扑独立

rsvp-te的作用:预留带宽+分配标签
约束计算:在源到目的的路径上,根据条件进行二次计算,so称为约束算法。
如果网络中部署ldp,就可以基于cr-ldp来实现te的功能,通过cr-ldp为mpls-te分配标签,也可以实现带宽的预留。但cisco不支持cr-ldp,华为支持。


Mpls-te本质就是建立一条端到端的lsp tunnel,通过该tunnel来转发流量,单向的。te的tunnel
通过ldp建立的端到端的lsp,可以理解为ldp的tunnel,通过隧道来转发流量
除了以上基于标签的tunnel,还有基于ip的tunnel,如gre,实现了ip over ip。ipv6中,有6 to 4 tunnel,6rd tunnel
隧道抢占:在一台设备上创建了多条mpls-te隧道,是具备抢占功能的-和优先级有关

backup和frr都能起到保护的作用,但应用于不同的场景
原点a(流量始发点)感知master路径down,就将流量切换到backup。但如果故障出现在原点后面的环节-a无法感知,backup就不能起到快速切换的作用,这时可以用到frr-可保证非直连的链路/节点间故障的快速切换。
——————————————————-
2023-02-21 17:06
Video 45

源点到端点(源到宿)的路径,是通过cspf算法计算 。在计算路径前,先要满足约束条件,满足条件后再进行spf算法。

路径计算组件:使用spf算法计算一个从源到目的的符合条件的路径-这个条件就是约束条件
报文转发组件:负责 te-tunnel建立完成后,如何让流量通过tunnel进行转发。

蓝括号是cost
需求:在1-4间建立mpls-te的tunnel。Mpls-te需要执行c-spf算法计算从源点到目的的最短路径的,首先就需要收集链路和节点信息构建map(参照ospf和isis ),这些链路和节点信息是由igp(ospf和isis)提供的。有了这些信息后,通过c-spf算法,计算以我为根到达目标的约束的最短路径。
约束是指需要先满足我的条件后,这条路径才能计算。
te有一个功能,保留带宽。(因为在lsp建立前已通过rsvp报文预留的带宽)
比如需求,从1到4要预留20M带宽。igp根据cost选择,只能走下面。而要te保留20m带宽,只能是走上面,这就是c-spf算法。通过c的约束俩选择出一些路径,如果选择完有多条路径,还需要通过spf算法来进行计算。
路径选择完后要在源和目的间预留带宽,分配标签构建lsp-需要rsvp-te协议来实现。
源点设备s,向下发送rsvp报文告知其预留x带宽,5收到后继续发送给其下游6,如此直到端点 e。端点收到后,会反向发送rsvp报文,通过该报文进行资源 的预留和标签的分发,建立一条从源点到端点的lsp,同时也预留的带宽。
rsvp中会区分不同类型的报文,1到4是pass报文,而往回发是receive报文。通过receive报文来进行资源的预留和分发。
tunnel建立之后,需要通过报文转发组件来实现引导后续流量经过tunnel转发。实现方式如下:
1.static的方式,配置静态路由,outif选择mpls-te的tunnel接口
2.通过pbr的方式重定向
3.自动路由-auto route。是在igp进程(ospf isis)下做的配置,实现ospf和isis自动的将流量引入到mpls-te的tunnel中
通过图中4个组件,就实现了流量通过te的tunnel进行转发。tunnel还支持一些高级特性,如frr;隧道备份-主隧道故障后可以进行快速的切换,但这种特性仅局限在原点,只能在原点建立主备两条隧道,在原点发现主路径故障后,切换到备份路径。
本质:backup是针对隧道的备份;而frr是用于保护节点和链路的
重优化:定时或者根据事件触发链路信息的通告,链路发生变化后,te可以重新计算路径,将流量切换到最新的路径上。重优化的方式:手动、定期、事件、关闭

路径计算时,先计算c-先计算满足条件的路径,在这个基础上通过spf算法计算源到目的的最短路径
Mpls-te 配置
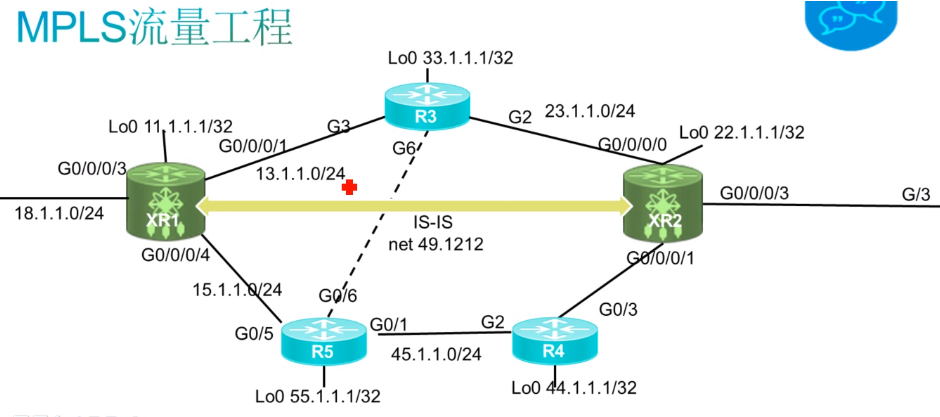
需要在xr设备间建立mpls-te的tunnel
ios平台配置命令

现在的设备已默认开启了ip cef(快速转发),开启ip cef后就会开启fib表项,如果不开就是进程转发 。而标签转发是基于fib的,只不过出去的时候会关联标签。

cisco中,mpls ip有两层作用:1.在if下开启mpls转发功能;2.在if下开启TDP(ldp)功能.
在mpls-te中,使用的标签分发协议是rsvp,跟ldp没有关系,但是会用到mpls ip命令的第一个功能,开启mpls转发。xr中这两个功能时分开的设置的。如果不配置mpls ip命令,tunnel可以正常建立,但流量不通。
只需要用到前面的total bandwidth来指定接口下需要预留的带宽,而 total 指在接口上面需要指定用于分配的带宽有多少,比如if是100m的,然后你指定了10M,那这个if只有90M带宽可以用。
Single-flow是基于每条流的带宽保证,主要用于qos,暂时用不到

Type6 lsa用于组播,

Ospf 为了支持te,增加了Opaque lsa,包含三种类型,根据你想要的泛洪范围,可以选择不同的opaque lsa。te中只会用到10,链路信息和节点信息只在区域内进行传递。但te也支持多区域和跨区域部署
如果使用了gr功能(用于nsf),会用到9类lsa。开启gr功能,告知对方我处于gt状态,就需要通过9类lsa来通告,因为是在peer间传递。

需求:在1-3间建立te的tunnel,想指定路径,可以通过cspf算法计算,或者指定显示路径。
显示路径:给设备指定nh,nnh为谁,然后就需要知道nh的信息-这是通过ospf 来传递的,通过te-router id来唯一的标识一台设备。在指定nh时可以把nh的te-rid加进去。在通告的时候不仅通过设备的r-id,还会通告链路信息。
ex:1-3走2,如果添加2的r-id,因为到2有两条路径,可以通过crspf计算出来,如果想让其走1,就不能指定2的r-id,需要指定2 的接口ip地址-把l1的ip地址添加进去,so在ospf中不光通过r-id来通告节点信息,还需要通告链路信息-把链路的ip地址通告过去。这样就便于在配置显示路径时,来指定经过哪条链路来到达。
opaque在gr,mpls-te,sr都应用到了


为te tunnel预留的带宽
Pass option-源到目的路径的计算方式
lockdown,关闭自动优化,链路带宽变化,并不会更改路径

Prority 前面是创建优先级,后面是保持优先级
Path-option,默认以10为步进,类似al从小的option开始匹配,/针对一条tunnel可以配置多个路径

开启宽度量后,isis会多了3类tlv,22,134,135
22:isis扩展tlv,通告设备信息
134:ip可达性tlv,通告链路信息和路由前缀
135:通告router-id。因为te里需要通过nh的r-id,而isis本身没有r-id,又不能使用system-id,so使用135tlv来承载rid
xr的te配置

Auto route announce,用做自动路由的,用于流量的引入-通过igp把流量引导到tunnel中传递
Dynamic 用cspf算法计算从源到目标的最短路径



正常情况通过te的lsp来承载流量只需要一层标签,te存在两层标签的情况主要用于te frr
cspf在计算前,先要看哪些链路满足我的条件,看预留带宽,筛序符合条件的链路,再通过spf算法计算到达目的的最短路径,正向发送rsvp报文,反向回复rsvp报文预留资源,分配标签,建立te lsp(tunnel 带宽),
——————————————————–
2023-02-23 11:29
Video 46 lab
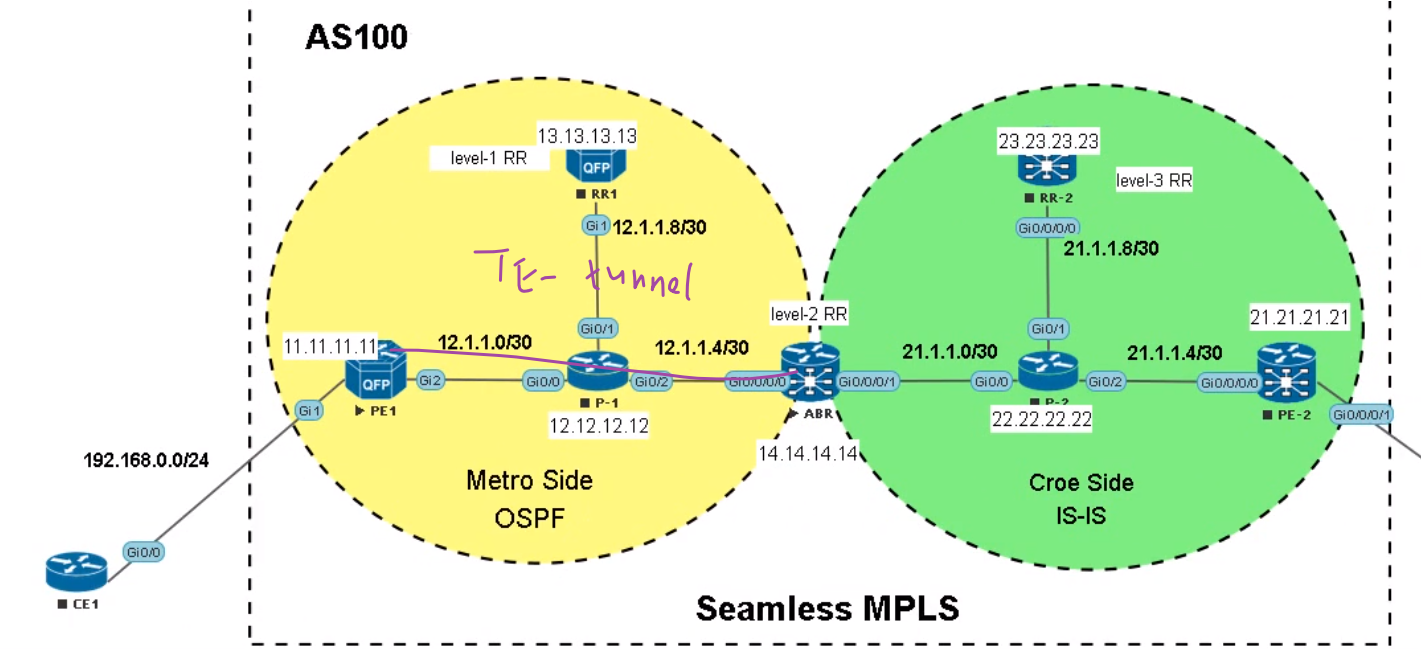
需求:在pe1-abr之间建立te-tunnel
evpn只是bgp的扩展。evpn主要是针对mpls evpn和vxlan evpn。sr和evpn没有关联


te的tunnel是单向tunnel,gre是双向tunnel(check why)

从此图查看,te-tunnel只会为tunnel的出口分配带宽
——————————————————-
2023-02-23 12:53
Video 47
igp的网络,是网络工程,因为其无法针对流量指定路径。
除了te,pbr也可以指导流量转发,但缺点:需在源到目的经过的每一台设备上都配置pbr策略。
而te的转发路径,是从源点进行指定(//类似tp的源宿指定),在源点和端点之间做带宽的预留和标签分配,流量就可以按照指定路径转发了。sr的实现方式和te是相同的

在igp网络中,想指定从源到目的的转发路径,唯一能做的就是修改cost值,但会影响所有流量。igp的cost是基于带宽进行计算,所有流量都走cost小的链路,最终会导致链路拥塞,继而丢包。igp(ospf和isis,eigrp除外)无法做到参考链路拥塞重新选择路径。当前指导流量转发,用的就是te。但te也很落后了,当前主用sr。
te在选路中,除了使用带宽,还有亲和属性(这里就是链路类型)。如速率:卫星链路、高速链路、跨省链路啥的。都可以作为约束条件。
Mpls-te(从名字可以看出转发路径是基于标签的),先选择符合约束条件的链路,如果存在多条,就进行spf算法进行计算,如果还存在多条,就通过仲裁选出唯一的一条。即mpls-te的转发路径,有且只能有一条,不存在负载。选择完路径之后,需要分配标签-rsvp-te(对rsvp的扩展,不光可以预留带宽,还能分配标签)

trunk口也可以实现地址借用。如果多个trunk接口都配置地址借用,且都借用同一个地址,会发现这几个trunk接口使用的是同一个ip地址。而以太口不行。trunk口都是点到点的,封装协议为ptp(通过ncp协议将if的地址通告给peer)或hdlc(将地址宣告进igp进程),不需要mac地址,而以太口,以太2型or802.3,必须有mac地址才行。
te的价值:te相对ldp可以指定转发路径,和预留带宽,具有frr等特性。
Mpls-te的信息发布组件


如果不配置接口下te的metric,te-metri就等于igp计算的metric (这是指源到目的整条链路累计的metric)如果不想使用igp计算的metric,就在if下指定te metric-用于spf的选路计算
优先级,用于实现te tunnel带宽 的抢占,越小越优。可以把优先级高的预留带宽抢过来,我用,我就up,对方就down了
亲和属性:就是为链路打标记

在eigrp中、ospf、te可以通过bandwidth调整接口带宽(仅是逻辑值,影响协议计算),端口的物理值不会改变,但协议会参考这个逻辑值进行计算,这个对转发速率没有影响。
ex:接口是1g的,但我通过rsvp只预留了100M,所以只有100m是可以用于te分配的


te的三大好处:指定路径,预留带宽,frr


创建新tunnel时,如果带宽存在抢占,将新tunnel的创建优先级和原有tunnel的保持优先级做对比。你的创建优先级比之前的保持优先级小,就能把对方的tunnel带宽抢占过滤。
保持优先级够低的话,就能保证不被别人抢走带宽。
——————————————————————–
2023-02-24 23:23
Video 48

隧道优先级越小越优,抢占功能默认开启且无法关闭。
igp在通告链路信息时会同时通告接口下的带宽信息:物理带宽信息和可分配的带宽信息/预留。预留带宽信息里又分8个优先级,越小越优。

ex:为if预留100M带宽,则isis/ospf在通告链路信息时,level 0-7的剩余带宽都是100m,当为level-7划分50mM,level-7的剩余可用带宽就变为50M,而其他level不变,还是100M,因为低优先级可用抢占带宽。反过来,如果为level-0划分50m,则因其优先级是最高的,其他level-无法抢占其预留带宽,so 其他level的预留带宽都变为50M


预留的带宽100M,分配的带宽100M,100%分配了,maxsub/最大剩余带宽为0

如果满足抢占条件,t-1会抢占t-0的1M带宽。Tunnel0就会down,然后重新进行计算。建立优先级和保持优先级。

看低优先级的隧道,被抢占还能否up,如果up,则能够继续转发;如果被抢占之后没有其他带宽可以分配,走其他路径,则down、
mbb原则(te tunnel一大特点,软抢占,相比ip frr不具备该特性)
硬抢占:不管低优先级隧道的业务,直接将带宽抢占过来;软抢占: 先创建te tunnel,将低优先级的流量切过去,再拆除低优先级原有的tunnel,释放带宽给新的tunnel用
即亲和属性

可理解,每一个属性就是标识一种链路类型,后续在te tunnel里选路时,就能指定te tunnel走哪种类型的路径,ex:光纤,卫星,微波…

首先需要在if下配置亲和属性标记:红色为1,蓝色为2
第二步配置亲和属性和掩码

在te tunnel 接口下去配置亲和属性和掩码。
首先给链路打上亲和属性标记,然后在tunnel里指定tunnel所需经过的链路类型,即属亲和性和掩码,其实现和acl很像

ex:让tunnel 1只走红色链路/2只走蓝色,为实现需求,在tunnel下配置亲和属性和掩码。然后如何选路?igp在通告链路信息时,会同时通告亲和属性的flag。我们把 配置的标记00000001和链路上的标记做与运算(用掩码来做的),掩码为1必须匹配,0可以忽略(和acl正好相反)。通过该方式就可以指定tunnel走哪种类型的链路

if配置亲和属性标记-class color:只不过给链路着色,不同颜色代表不同类型的路径

就去比较链路信息中有哪个,这三个位全部match(te的亲和属性,掩码和链路的亲和属性标记),这条链路可以被选择。

默认使用te metric(默认=igp metric)来进行选路,也可以配置来使用igp的metric

如图,A-B间存在两条链路,调整te-metric为10 和1后,就能 选择下面的路径了(原来按照igp的cost,走上面开销小的路径)

第二章,什么时候发布信息


周期性泛洪的时间由igp来决定,默认ospf的泛洪时间1800s,isis 是900s
带宽变化有两种,up:增长;down下降。指可以设定带宽上升或者下降的带宽使用门限,超过门限报警。
周期性;链路发生变化;带宽发生变化;cost值发生变化;隧道建立失败

更改了周期性泛洪时间


up:每隔15%一个门限-每超过15:%就进行链路通告
Te 的源节点,收到链路信息后会重优化,这就是为什么要周期性通告链路信息。这也避免了像igp一样,所有的流量都走cost小的,导致拥塞。通过周期性通告链路信息,实时优化路径,就不会出现拥塞了。

可以针对te单独设置链路泛洪周期
三信息发布


默认te metric=igp metric

只是在te中用到类型10的lsa,9(链路泛洪),10(区域内),11(as内)的泛洪范围不同罢了。
opaque lsa可以支持tlv,是模块化的。Opaque las的目的就是增强了lsa的扩展性
类型9用在gr上,类型11用在引入外部路由上。sr会用到10 和11类。
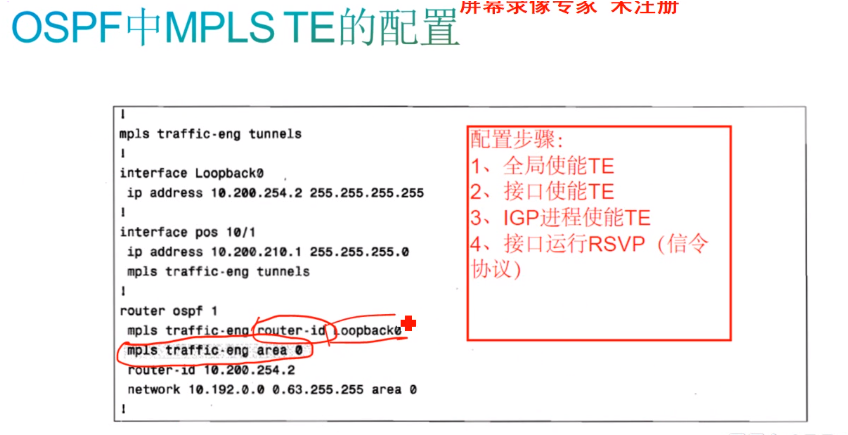
在哪个区域开启ospf te功能,指定te的r-id(用来标识设备,但不要求路由可达)

option字段里存在o bit位(opaque);te metric默认=igp metric

通过opaque type 就能知道支持什么特性,很多featue都能通过opaque进行扩展
Admin metric-te的metric
Max band是if的物理带宽
———————————————————-
2023-02-28 11:00
Video 49
本章讲 链路状态信息传递方式+cspf算法的计算方式

继续讲ospf-te和isis-te
ospf Opaque lsa 使用了Type1和type2两种类型lsa,分别通告以下不同的内容:



Isis-te

即,开启宽度量,才能支持te,会启用3中新的tlv

针对哪个level开启mpls te

窄度量只有1B,且前两b有固定意义(up/down bit,用来防止路由环路;internal和external,用来表示内部和外部度量值的,置零代表内部度量值,置一代表外部度量值),so只有后面的6b才能标识metric,26.

Is 可达性tlv,通告节点信息-告知到达节点的距离

ospf-te以及isis-te泛洪之后的结果

流量工程信息:如接口的带宽信息。TEBD的链路信息是由igp通告的,增加了一些用于te选路的信息。

泛洪时还会通告link的flag信息(用于te的选路)
路由器进行链路信息泛洪的条件:周期性泛洪;链路发生变化泛洪;链路的cost发生变化发生泛洪;超过或低于带宽使用率的阈值;te tunnel建立由于带宽原因建立失败。
本质就是,ospf和isis针对现有的链路信息进行扩展,在基础上增加te选路的信息,泛洪。在本地生成TEDB,在这里保存te用于选路的链路信息,进行后续的链路计算。


静态-通过手动方式制定显示路径

链路属性即亲和属性。首先根据这三个条件选出符合条件的链路。比如有10条链路,根据约束条件选出了5条,再针对这5条进行spf算法,通过spf算法计算出从源到目的的最短路径。如果经过spf算法还有3条,就通过仲裁原则选出唯一的一条。te中,最终只能选择一条作为转发路径,不可能存在负载


计算逻辑:先看是否满足c,满足之后再进行spf计算
cpsf算法结果不会影响到igp 的spf算法结果。并且要求spf算法在cspf之前完成(先计算igp的spf算法,其计算完成后才会计算cspf算法)

ex:在1-4间Te tunnel建立完成后,设置te-metric为1 ,由于te-tunnel if也在ospf或isis 中,但并不会影响igp之前从源到目的已经建立好的路径(1到3还是走上面,不会走te tunnel)


ex:有5条链路满足要求,在a-z之间建立te tunel。左右的metric都是10.根据上述仲裁原则,最后会随机选举最后两条路径。te是不可能存在转发路径的ecmp的。
—————————————————————
2023-02-28 22:54
Video 50
想要ospf和isis支持te,就需要在ospf和isis下面开启支持te功能,才能通告用于te选路的链路信息和节点信息。
te里带宽有两种:if下配置的带宽,可理解为rsvp的带宽-用来实现给te分配的带宽,如果不指定,默认是物理端口带宽的75%,用来预留给te使用;第二种带宽,在te tunnel里需要配的带宽 -在建立te tunnel时为te tunnel分配的带宽是多少。if下预留的带宽如果不够用,这个te tunnel是无法建立的
Te tunnel的优先级:建立优先级和保持优先级。用于实现资源的抢占
te里支持链路属性-亲和属性,给link打标记,标记链路类型。在建立链路时,指定可以走哪种类型的链路。即通过亲和属性的方式匹配链路标记,确定转发路径走哪种类型的链路,在te tunnel建立时规定tunnel的转发路径的链路类型。

affinity bit=attribute-flags

te计算需要通告node信息和链路信息。node信息就是一台设备,通过router-id的方式进行通过;通告链路信息,需要指定通告哪个区域的链路信息。如图为,将area0里符合条件的链路信息通告为te的链路信息。如果if开启了te功能,且正好在area0中,则该端口的参数才可以作为te的选路参数通告出去。
te的约束条件只有可用带宽和链路属性。只有可用带宽和链路属性都满足的情况下,如果还存在多条链路,才会通过te metric进行优选。

Step1. 通告节点信息和链路信息;2.使用cspf算法进行路径计算;3.为tunnel预留带宽资源,为转发路径分配标签,从源到目的建立一条te的lsp。
rsvp本来是用在qos中的,qos有三种模型:fifo,集成服务模型,区分服务模型。te需要提前预留带宽,so 在te中又使用了rsvp-te,是rsvp针对te做了扩展,可理解为完全不同的协议。类似于isis。isis早期用于csnp网络,用于osi的网络层

显示路径:手动指定从源到目的的转发路径//类似于tp的逐站配置。

在本端把nh的r-id或者if的ip地址添加进去(4上需要指5 的if ip)。此为严格下一跳:指定直连下一跳 。默认就是strict模式
松散下一跳:1上指定nh为5,5的nh为3。1-3因为不是直连的,so只能配置为松散下一跳,so通过cspf计算到达5的路径。这种需要配置loose的标识,如果不配置,肯定建立不起来。因为需要将配置的显示路径,发送给rsvp,由rsvp沿着这条路径进行带宽资源的预留和标签的分配,如果提供的路径有问题,就无法做到资源的预留和标签分配

igp通告用于te选路的信息,会包括node和link信息。node就是root-id,而link是把链路所在的接口地址通告出去。即通过router-id来标识1台设备,通过接口ip来标识link。
设备之间通过单链路互联,可以指定nh为root-id。如果设备之间是通过多跳链路互联,就需要明确指出要通过哪条链路到达对方,即需要把对方的ip地址添加进去。

指定的r-id或ip只要在TEDB中存在即可

nh可以配置r-id或ip地址
配置完显示路径后,需要在tunnel中调用该显示路径。如果想使用显示路径,需要把path-option的 index值调低。如果在一个tunnel里到达destination,存在多个pass option,就说明指定的多跳转发路径都可以到达对方,会优选index值最小的。如果pass option 1 路径故障了,会继续看下一个pass option,为dynamic-需要通过cspf算法进行计算。
这种为现网用的比较多的配置,先为tunnel指定你让他走的转发路径,然后再配置一个dynamic。如果转发路径down了,就说明显示路径挂了,需要等待cspf算法自动计算另一个路径,再去实现数据转发。链路故障时会导致tunnel down,但是在通过动态方式计算路径后,会重新up起来。

————————————————————–
2023-03-01 14:21
Video 51
本节讲解 rsvp的报文类型,常用的tlv,作用等。
在跨区域的te-tunnel建立中,只会用到显示路径,不可能使用动态计算的方式计算跨区域的te-tunnel。cspf算法也是只能计算一个区域内的。//igp本身只能计算as内部的

在众多link里先通过约束条件选举符合条件的链路,条件:1符合带宽;2符合亲和属性的要求-为不同链路标记了不同的类型。选择出来后进行spf算法(check 这个计算spt树不就是根据te-metric还是穿的igp 的metric计算的么?怎么仲裁还会比较te-metric?),计算从源到目的的最短路径,如果有多条,利用仲裁选举唯一的一条最优路径(依次比较te-metric;比较igp metric;比较剩余最大的可用带宽;跳数;随机)

带宽比较也是一跳一跳的//理解中间有分叉路线吧,比较路径的剩余带宽最小值?check?

隧道重优化

重优化:可理解为选择一条更优路径。

1-3之间已建立te tunnel 30M,当1-4连线后,就出现一条更好的链路到达3,这就叫重优化。重优化有三种模式。自动重优化(周期性):每隔1h自动进行重优化,到达重优化的时间点会自动进行重优化。上图重优化1走4到达3,并不会导致流量的中断,因在重优化的过程中存在mbb的机制。先计算从4到达3,然后告知rsvp-te,让其建立1-4-3的转发路径;再把流量切换过来;在将之前的转发路径删除(释放之前的资源)。该mbb过程可以保证切换时不丢包,保证业务的可靠性。即每隔一小时重新计算一次源到目的的最优路径,如果计算后和之前的结果不一致(类似存储的增量备份比较),则进行切换。切换时用到mbb机制。
手动重优化:1-4间链路up,但还没有到达自动重优化的时间点,可以通过手动方式进行重优化。也会触发mbb机制,只不过不需要等待超时时间,马上切换。
日志重优化:ex收到1-4间链路up的日志,这个日志也会触发重优化,自动的,流量也会切换过去。

链路(恢复也可以触发重优化,回切的快慢取决于用的是定期重优化,还是事件(日志)驱动重优化-1,3之间故障的链路up后,只要1(ingress节点)收到3 up的事件后,会自动进行重优化,回切到3。


3.日志重优化。但如果链路震荡,会发现te很不稳定,切换的过程还会造成丢包。这里面mbb只用于回切,正切是没有的//说明无法提前感知故障,当发现故障,重新计算,构建一条新的转发路径,so,正切业务必断。mbb(make before break),但正切是业务已经break了,所以就没用到这个。

转发路径为1-3-4,当1-3链路中断,正切,需要重新计算,从1-4建立转发路径,必然丢包。而当1-3链路up,是回切,才会有mbb机制,回切肯定不会丢包。如果链路不稳定,会导致一会正切,一会回切,流量一会丢包,一会不丢包。造成业务不稳定。为了保证业务的稳定性,不建议开启日志重优化。

另一种关闭重优化的方法,选择定期重优化,而时间设置为0。

第三个模块是RSVP
第一个模块,如何发布信息,如何构建用于cspf算法的地图,这个地图就需要用到node信息和链路信息,通过igp协议来通告节点和链路信息,只能使用链路状态选择协议,isis和ospf。第二模块,有了上述信息后,通过cspf和显示路径来计算源到达目的的最短路径。第三模块,资源预留,有了路径之后,将路径发送给rsvp,通过rsvp进行带宽的预留和标签的分配,就生成了从源到目的一条te 的lsp,才能转发流量。第四步是如何实现数据转发。第五部分,路径建立,即资源预留

Te里用到的是rsvp-te。rsvp的扩展性差(看上图),因为其需要提前预留资源,同时转发路径上的所有设备都需要支持,如果不支持,她也不支持资源的预留。另一点需要预留带宽,占用-即使不转发流量。所以qos 没用rsvp,当前主要使用区分服务模型,即PHB。
CR-LDP:约束的LDP,针对ldp的扩展,通过ldp的方式进行资源的预留和标签分配。比较新的协议,不太成熟,基本没人用。
cisco用到te的信令协议只有rsvp-te,但华为都支持。

rsvp是基于ip承载的协议,so 不可靠-因为ip无法做到可靠性保证。ospf同理。而bgp是基于tcp的,由于存在序列号的机制,来保证了可靠性。so在bgp中,协议本身没有为可靠性做出什么实现。但ospf协议本身 ,就为可靠性实现了很多东西。ex,在dd报文交互时要选举master和slave-就是为了保证dd报文交互的可靠性-通过序列号的方式来保证dd报文交互的可靠性;lsa ack(bgp在发送update之后,不需要发送ack,因为其可靠性机制是通过tcp实现的,tcp就存在ack)。
总结:凡是通过ip承载的协议,由于ip没有保证上层协议的可靠性,都需要上层协议自己来实现可靠性的保证。rsvp也是如此。
路由选路本质上都是通过igp,而在te里会同时通过igp和cspf算法进行选路。
区分服务模型是针对转发层面进行控制,如做shaping或placing做限速,而在rsvp-te是没有这些限速机制的。check,一个是针对流量的,另一个是针对控制层面形成隧道的。

2205是rsvp的标准rfc

Pass error的发送场景:1.收到pass报文(下游接收到),但检查path报文有问题,就会向发送方回复pass error 报文。2.link down后,我主动通过pass error通告上游设备link有问题,需要重新进行计算。
rsvp的上下游同ldp的上下游,看流量的走向来确定。
pass报文,由源1(ingress)开始发,到2,在2重新生成pass报文后再发给3。如果2-3间链路断开了,需要由2向上游1通过pass error提醒1链路有问题,需要重新计算从1到达3的转发路径,在将流量切过去。//都是从ingress节点开始计算,可等同理解为需要通过igp选择一条新的从ingress节点到egress节点的最优路径。
Pass 报文是上游发送给下游的,receive是下游发送给上游的。

在1-4之间建立te 的tunnel。需要在ingress节点1 将计算好的路径(通过cspf算法or显示路径)发送给rsvp,rsvp会沿着提供的转发路径进行资源的预留。rsvp会沿着提供的转发路径进行pass报文的发送,如1会给下游设备2发送pass报文。2在收到pass报文后先检测pass报文的有效性,如果pass报文有问题,会丢弃并向1回复pass error。如果没问题,则2重新生成一个pass报文,继续延你提供的转发路径发送给下游的3,以下反复。从1到4(ingress到egress)就是pass报文的转发路径。4在收到pass报文后需要往回发送receive报文,在报文中,会通告4为该te tunnel分配的标签,并且上游接口在接收到receive报文后会在端口上申请对应的带宽。实际在发送pass报文时已告知tunnel需要申请多大的带宽,然后receive报文中也会携带需要申请的带宽(只不过使用了不同的字段),逐跳返回到ingress节点。ingress节点在收到receive报文后,再标识tunnel的资源预留和lsp已建立完成,tunnel就是up的。如果ingress接收不到receive,tunnel就是down。
下游向上游发送receive报文时,如果receive报文有问题,则上游会向下游回复receive error报文。
前六种报文是rsvp公有报文,而resvconf(confirm)和resv tearconf都是cisco私有报文,目的是为了保证报文转发的可靠性。由于rsvp是基于ip的,ip没有可靠性机制,在下游发送receive报文后,上游接收到向其回复resvconf报文用于确认接收到了。pass报文的可靠性是通过receive报文来实现,如果有问题,会收到下游发送的pass error,如果没问题,就能收到receive报文。Receive tear conf类似,用于接收到receive tear报文的确认。
即便上述两个是cisco的私有报文,cisco和else厂商互通并不会存在问题,因rsvp是基于tlv的结构,tlv的一大特点就是如果本地不支持的tlv可以忽略。比如isis一段开认证,另一段没开认证。比如cisco这边没有收到resv conf或resv tear conf也不会影响,还是会正常建立rsvp。
hello报文是扩展报文,主要目的是作为keepalive报文使用。两台设备之间,多久时间没收到keepalive,就会认为链路故障了,告知te(//ingress端就会重新进行计算)重新进行计算,需进行路径的重新切换。 hello报文的发送间隔是ms级别的。有些厂商可能不支持bfd绑定rsvp。因为bfd检测也是ms级别的,rsvp也是ms级就不需要依赖bfd进行检测了。但华为是支持bfd绑定rsvp。

报文的收发统计,ack是receive tear conf

ingress节点通过cspf算法计算之后,将计算完成后的路径发送给rsvp,rsvp会沿着该路径发送pass报文,直至到达egress节点。egress节点回传receive,通过receive报文进行资源的预留和标签的分配。如果哪个接口收到了receive报文,会从该if上分配带宽,在receive报文中就携带了需要申请的带宽,ex:10M,2在收到3发来的receive报文,会从接收的if扣除10M,将这个10M用于te tunnel的保留带宽。
receive报文是一跳一跳的,如r3发给r2,s ip时r3,dip就是R2。//理解,因为你要从egress节点,逐跳向上分配标签,所以只能一跳一跳的。而在上游发送pass报文向下时,只是信息的通告,我想要什么资源,从源到目的即可。
而pass报文,从源到目的转发路径上,报文发送的sip和dip不变,中间设备在重建pass报文(需要改一些报文的内容,需要重新生成)时,也不会改变pass报文的sip和dip。

Rsvp nei关系发现和建立是通过pass和receive报文来确定的,而hello报文仅用来keepalive。

dod是标签的通告方式,另一种是du (下游随便发,流量是从上游-下游的)。Dod (上游先申请标签-我有到达这个目标的需求,下游再通告),下游按需回应上游的请求某fec的标签。
因rsvp支持的是dod,so在pass报文中就会存在label request tlv,告诉下游设备我需要标签。
标签的分发方向是从下游-上游的,向流量的出口方向。
已支持为显示路径进行资源的预留和标签的分配。
记录lsp tunnel经过的每个节点,称为root record。(可理解为as path)
Ipv4标准长度20B,可以扩展到60B,每一行4B,头部长度15,即60B。tcp也是一样。在ipv4中可以扩展到60B的原因是因为在ipv4里会携带一个option,用于携带扩展内容,其中就有路有记录。路有记录可以用于防止报文转发环路,每经过一台转发设备,都会将经过的出接口的ip地址记录下来(逐跳追加)
rsvp也支持root record,在pass和receive报文中都可以开启root record功能。ex在pass报文中开启该功能,则在经过每一台设备后都会记录报文转发的出接口ip地址,一个个加进去,用这种方式防止环路的问题。另一个重要的功能就是用于frr,不仅可以记录ip地址还可以记录分配的标签。te-frr有链路frr和节点frr,在节点frr中就会用到root record里记录的标签,来实现frr的功能。
Root record不仅可以用来防止环路,还能用于frr机制。

对象就理解为tlv,之前rsvp没有的,是针对rsvp-te扩展的
通过cspf或显示路径规划从源到目的的转发路径,然后将转发路径发送给rsvp,rsvp通过指定的转发路径进行pass报文的发送,进行资源预留和标签分发。转发路径会被包含在explicit route tlv中。
Session attribute中的0x02为1,就说明需要在root record里记录标签
se:共享资源
Session attribute tlv标识了te支持什么功能。可理解为flag位

swalls应该写成sender template//详见 基于mpls的流量工程
Session tlv中还会包含tunnel 扩展id
最重要的几个参数:sip ,dip, lsp_id,隧道id ,扩展隧道id。通过5元组就能唯一的标识一条隧道。

session字段在pass和receive报文中都存在。上图ipv4地址为egress端点设备的ip地址。


主要包含在pass error中。在发送的pass error中,通过error spec来告知对方因为什么原因导致path error,ex:链路down,资源不足,显示路径不可达,nh非法等。//类比icmp的 type和code



一共有三种类型的style

cisco仅支持se,华为全支持

如设置保留带宽为50M,需求在1-4间建立te tunnel,要40M,走1-2-4没问题。现在需求变为80M,重新选路,存在mbb机制,重新计算选路,1-3-4,进行资源的预留标签分配,建立lsp之后将流量切过来,在将之前的te tunnel拆除。
但是拓扑变为右侧就有问题了,还是先申请40M。走1-2-4,资源分配之后,2上流量的出接口的剩余带宽就变为40M了。需求变为80M之后,走1-3-2-4时,2 的出if只剩下60M,不能满足80M的需求。这种场景是否意味着mbb做不了?可以把之前的路径拆除,将资源释放然后再重新申请,但这样会带来的问题是,拆除的过程中流量会中断,业务就会down。现在想不中断业务。解决方案就是资源的类型。se(存在于pass报文中),前提是必须是同一个tunnel,tunnel1和tunnel2是不能共享资源的。ex:2这台设备在分配资源时,如何判断是否同一个tunnel来申请的资源?需要用到5元组 sip,dip,lsp id,tunnel id,扩展tunnel id。最重要的是扩展tunnel id,把带宽改变之后,在发送的pass报文中,tunnel 扩展id不变,lsp id可能会变,其他几个信息也不会变,由此可以判断出是否为同一个tunnel。如图中的情况,判断为同一个tunnel,就可以共享资源,2的出if只需再拿出20M,建立lsp。
两种方案,需要由40M变为80M。1.直接再申请40M带宽资源。2直接申请80M的。2方案较好,如果是方案1,只申请40M,就不会用到资源共享,但有个问题,在申请这40M的转发路径上(如走1-3-2-4),1-3只会为其分配40M而不是80M。因为pass报文中只申请40M。so需要用到方案2。80M在这种存在资源冲突的接口上,利用共享的机制去共享资源。
WF和FF都是资源独立,不管是否来自于同一个tunnel,都不能实现资源共享,只能把之前的tunnel拆除,才能重新建立-先释放资源,再重新使用。过程必然导致业务的中断。

flowspec只会用到平均速率:理解为需要申请的带宽,主要在receive报文中,pass报文中也会有,但不叫flowspec(叫sender-tespec)。即预留多大的带宽在pass和receive报文中都会有体现,只不过用的不同类型的字段。


只存在于pass报文中。

ero。包含计算出来从源到目的的路径,及显示路径。如果显示路径有多条,则每一条ip前缀都会占用1条。
L位置一代表松散地址(指定的nh不是直连的),置零代表严格地址。在指定显示路径时,需要指定nh,松散的还是严格的,这些在报文中是有体现的。

主要用在pass报文中,有比较重要的flags
下节讲 rsvp的路径建立过程,拆除过程,mbb-ex:在资源不够的情况下如何实现资源的共享?需先判断是否来自于同一个tunnel,判断方法5元组
共享显示保留类型:se

在资源不够的情况下,需进行资源的共享,怎么罚?是重新申请一次整体的资源。
Te 除了frr的可靠性机制,还包括如何建立backup的lsp,backup的lsp如何实现链路和节点保护-frr的机制。Qos-te,涉及dste-区分服务te。
域内或跨域te

—————————————————-
2023-03-03 17:01
Video 52

te里的有4个组件,1.路径通告-通过链路状态选择协议通告节点和链路信息。ospf和isis需要在协议下开启对te的支持,ospf和isis就能通告用于te选路的节点信息(通过router-id来标识节点。isis是通过system id来标识节点,isis里有扩展命令行可以通告router id,同时通过tlv 134来通告r-id)和链路信息了。2.te自己的选路算法,cspf。
isis在开启宽度量后,会增加22,134,135 tlv,22和135较常用,134用于通告router-id,标识一台设备。通告的链路信息包括:链路的地址,链路的类型,链路的最大带宽和保留带宽。
te的好处:1可以为流量预留带宽,通过rsvp协议实现;2te可以针对某一类的流量指定转发路径,igp就没有办法指定转发路径。修改metric可以调整转发路径,但是会影响的所有流量。3te- frr的功能,这点就是之前isp的网络,使用te的原因之一。 因之前在isp的网络中,想保护某条链路或某个节点,是没有任何机制的。
ex:isp网络中典型的组网时口字型网络,其不仅可以实现全互联,还可以实现用最少的链路达到最好的效果。另一种常用的就是日子型-两个口字型。这里的全互联,不是真的全互联,因isp很少采用交叉的方式连线,因isp的设备往往在不同的城市,不像dc里,你可以在机房内随意连接。isp的网络往往在不同的城市,每个城市之间都进行全互联,成本过高,so 运营商为了保证可靠性,城市间都会进行连接,其只要通过其他城市可以到达另一个城市就行,不需要实现真正意义上的全互联。
if上配置negionation auto,就能依靠其感知对方if物理故障。primary链路故障,直连端口故障,上报给igp,进行spf算法重新计算最优路由,如需要100ms。还需将最优路由写入到lc卡-线卡中,而rp卡是主控板。 报文进来是靠转发层面转发的,而并不是靠控制层面。综上,一条链路故障,业务的中断时间=故障检测时间+igp收敛时间+转发表项写入时间。

isp可以接受的最大限度就是50ms内的丢包,如何实现?通过te-frr。不仅可以预留带宽,指定转发路径,实现链路保护和节点保护。同时在链路故障或节点故障时,可以进行50ms的故障切换。
但现在因为ip-frr出现后,te-frr用的少了,因ip-frr可以为每一个前缀都计算一个备份路径,通过将备份路径提前写入到转发表项后,当主路径一旦down后,可以将流量快速切换到备份路径上。满足50ms的故障切换。
sr分成两部分:sr be 用来代替ldp的;sr te用来代替rsvp的te。
cspf算法,进行路径计算(第二个组件)。c,1要满足带宽要求;2要满足链路的亲和属性-为每一条链路打上独立的标签,后续可以指定tunnel所选择的路径的标签。在满足带宽要求和链路亲和属性的前提下进行spf算法计算,如果计算结果有多条链路,还需要执行te的仲裁,通过仲裁只能学到一条从源到目的的最短路径。计算完路径后,cspf算法会将计算后的路径交给rsvp(第三个组件),实现路径的建立。rsvp会根据cspf算法提供的转发路径,进行带宽的预留和标签的分配。
第四个组件,实现流量通过tunnel来转发。1.使用静态路由的方式把流量迭代到te tunnel。2.自动路由,在igp中配置auto route。3,通过pbr来实现流量的引流。
Mpls te采用的信令
原始的rsvp协议只能预留带宽,但不能分配标签;cr-ldp(相比ldp增加了预留带宽的功能),cisco和juniper不支持,仅华为支持
想要深入学习协议,就去参考rfc
rsvp的消息类型,path err。bgp中存在notification报文,如果在接收到open报文或update报文后,如果这些报文有问题,就会丢弃报文,断开session,向nei发送一个notification,告知其是什么原因导致session断开的,就能通过这个来判断问题是原因造成的。在rsvp的报文中也一样,Path err报文类似。
如果下游的出口不满足带宽要求,下游会丢弃pass报文,向上游回复pass error报文。使用cspf算法计算源到目的的转发路径,就不会有该类的报错,因为已经存在约束条件了。而如果使用显示路径的方法的话,通过手动指定转发路径,会按照指定的路径发送pass报文,会导致下游设备的出if不满足带宽要求,导致pass报文被丢弃,并向上游回复pass err报文
另一种情况,pass报文中携带的ero-显示转发路径(显示路径对象ERO(Explicit Route Object))

ex:指定的转发路径为1-2-4-3,1在把pass报文发送给2时,2怎么知道要把pass报文发送给4还是3?这就根据pass报文中携带的ero,ero已告诉你应该按照什么样的路径去转发pass报文。2在收到pass报文后,需要看ero看nh是谁,如果发现指定的nh我不可达,就说明你指定的显示路径有问题,会把pass报文丢弃,然后向1回复个pass err报文。pass报文在每经过一台设备,都会进行处理。
pass报文是需要每一台设备都进行分析处理的,比如1发给2 pass报文,如何告知2需要分析报文的。有两种方式:1.rsvp报文是通过ip报文承载的,router是通过dip查表转发,其通过ip头部就可以实现转发,不会看ip上层的内容。如果想让其看ip上层的内容,需要针对每一个ip包做拆包,工程量大,其每个ip包的解析都需要上报至rp板,由主控板去做拆解包,查看上层协议是谁。很费劲。如果利用protocol id 46(rsvp),设置只有在protocol id为46时才拆包,如果不是就放行走三层转发,但这需要后端实现,比如芯片去判断protocol id,如果协议id=46,就交给控制层面处理,会增加cpu和芯片的使用率 。更好的方法,利用ipv4的option字段,ipv4的头部长度是20B-60B的,option 字段中有一个router alarm选项,如果在ip报文中添加router alarm选项后,下游设备就好主动分析报文。这是ipv4天然支持的功能。so在rsvp中,想要下游设备分析报文,只需要在报文中添加router alarm选项就能实现。
这里提到igmp,因igmp需要路径分析,ex:发送query查询报文,查询报文也需要每台路由器去分析,so在igmp中,也需要在ip头部里追加router alarm的选项的,通过option来告诉我下游的设备,你需要去分析报文。

如果pass报文没有错,就会沿着ero所携带的转发路径继续向下游转发,直到到达目标节点。每个节点会向上游回复receive报文,包含一个label,label里可以填充显示空标签或隐式空标签。Ex 0-ipv4的显示空,2-ipv6的显示空,3-同时是v4和v6的隐式空。如果是1,则代表router alert,标签报文经过的设备都需要拆标签报文查看上层内容。0-15是系统保留标签,任何标签分发协议都能分这里的标签。mpls-te也会存在php的概念
ex:2在收到3的receive报文中的带宽需求是10M,3就需要在接口上,将可分配带宽-10M,用于tunnel的分配。2会重新生成receive报文,发送给上游设备1,会携带2为该tunnel分配的标签。
在接收到pass报文后,只是检查我的出接口是否满足带宽要求(只是进行提前检测),并没有预留带宽,只有在if上收到receive报文后,才会在接口上预留带宽(在if上减去需要预留的带宽)。
最终源点在接收到receive报文,tunnel 才会up。
Mpls-te,只是通过rsvp-te来分配标签,所有的标签转发机制都是依靠mpls实现的。
pass和receive报文会定期的发送,通过定期发送来维护端到端的tunnel,如果tunnel不用了,就需要释放标签资源和带宽资源。拆除过程存在两种报文,path tear和resv tear报文。正常情况下,pass和receive报文是每隔30s发送一次,有个正负的15s的时间差,避免大家都在30s时发送path或receive报文导致带宽占用率高的问题,因为需要考虑带宽和cpu的处理能力。ospf里有类似功能,称为ospf主步调。可以通过主步调的方式让不同的peer有发送时间差,不至于在同一时间全部都发送ospf的hello报文,而导致cpu使用率高的问题。So rsvp中也一样。
rvp中的倍数为4,如pass和receive是30s发送一次,则需要等120s才能知道邻居 down,故障检测时间太长,so引出hello,可以基于ms级的发送,也是4倍的hold time。所以在rsvp中,不一定用到bfd,只不过bfd可以track整个lsp的转发路径,而hello只是针对直连邻居的连接。
——————————————————————
2023-03-10 14:07
Video 53


申请的1M会在resv报文中携带。
收到pass和receive报文才会形成nei关系

dod,标签的通告方式

这就是常见的tlv。Explicit route就是ero,通告显示的转发路径。
Record route有两种使用场景:1.防环;2.frr-在节点故障的场景中,通告recorde route来记录节点分配的标签。
Session attribute包含在path报文中,以下为几个很重要的flag位。1.上游设备开启frr功能;2.如果开启record route,则该bit位会置位;带宽共享也会把该bit位置位;frr的类型,是链路保护还是节点保护,也需要在session attribute的tlv中的flag位置位进行标识。

ero,存在顺序性,第一条就是经过的第一个设备,后面依次

Session-attribute中会有8个bit的flag位来标识一些功能
路径的建立:通过cspf算法或显示路径来计算(最终都会生成ero,包含路径上所经过的所有设备),然后将路径发送给rsvp-te,rsvp-te再沿着指定的路径发送pass和receive报文

ero的顺序性(explicit route object),2在接收到pass报文后,根据ero来判断将pass报文发送给谁(从自身的nh开始算),显示路径会随着pass报文传递直到到达端点r9。

Path 报文中包含的tlv

R2在收到path报文后会重新生成path报文,但其源目的地址不会发生改变(如果修改,则tunnel的源和目的就变化了)

3收到path报文后,会向2发送receive报文(不是从目的直接发到源的)。
上图的 Record route就记录了转发路径上所经过的设备接口的ip地址(check,不应该是r2-2 if么?出if),通过该方式防环(如果route record列表中有自己的接口ip地址,那肯定就存在转发环路,就应该丢弃)和进行frr(记录转发路径上的标签,通过记录标签的方式实现节点故障的frr)


mbb用于tunnel的回切及tunnel的带宽抢占。上图为带宽抢占场景,从1-5建立一条带宽为30M的te tunnel,当前转发路径为1-2-5。45M和100M为整个if的预留带宽。
在r1上将tunnel 带宽由30M改为80M,只能选择下面的1-3-4-2-5,2的出if上现在只剩70M。如果此时在2收到80M的需求的pass报文是,会发现带宽不足,就会丢掉pass,并向4发送pass error报文,依次传递,最终到达R1。
解决方案:把原先的tunnel拆掉,ex1-5,先发送pass tear,把te tunnel拆除,释放带宽资源,然后再重新建立。这种可以,但是会造成流量受到影响。能否实现不拆之前的转发路径的情况下,又预留新的转发路径,实现切换时的不丢包,可以-需要使用se的机制(te的带宽使用方法:se(共享,现在用的都是这种。而cisco只支持这种,else厂商会支持其他的带宽使用方式);ff和f-这俩都是带宽独享的使用方式;)

如果设备不支持带宽共享,就只能先拆除带宽,再重新建立隧道,必然导致流量的丢包。
如果采用共享带宽的方式,就可以保证在切换到新的tunnel前,是不会丢包的。这需要源节点支持带宽共享的风格。在pass报文中存在session attribute的tlv,在该tlv中就会将se位置位,说明这个tunnel是需要支持带宽共享的。如果支持se的带宽共享的方式,如何实现带宽的预留?答:可以通过5元组的方式识别唯一的一条tunnel,sip、dip、s-tunnel、d-tunnel、lsp-id。之后接收到的pass报文中携带的5元组。同一个tunnel可以共享带宽,不同的tunnel是不能共享带宽的,只能实现带宽的抢占-需要查看你的建立优先级是否大于保持优先级

在建立tunnel时,是从源节点发送pass报文,直到到达尾节点。而在tunnel建立完成后,上下游设备会独立发送pass报文和receive报文,这个下游发送的receive报文并不是用于接收到的pass报文的确认,而是用于下游维护和上游的状态。如果在4倍的发送时间间隔-120s没收到,就说明链路出现了问题。为避免多台设备同一时间多次发送rsvp报文导致cpu占用率高的问题,才会有50%的抖动时间(+-15s),也就是15s-45s之间。只有在tunnel建立的时候,pass报文和receive报文才是有时序性的,一旦建立成功上下游就各自发送了,只是用于维护rsvp的邻居关系。



限制rsvp报文的发送频率。可以限制rsvp报文的singal 的rate limit,如果太大就可以将报文丢弃掉,该方式为了避免攻击。ex:设备被人攻陷后,会给你频繁发送receive和pass报文,针对每一个报文都需要分析,导致cpu使用率高。so会有rate limit的限制,比如每秒仅处理50个rsvp报文(不管具体的是哪种报文),如果超过上限,多出部分全部丢弃。而当cpu忙时,可以先将报文放入到队列中,等后期处理。
区域间的流量工程,只需要在配置显示路径时注意,另外就是链路管理。
Lab

需求:r1-r5间的区域内的te-tunnel;r1-r5区域间的te-tunnel
R1,4,7是xr
R1:
Router
Mpls traffic-eng 下把所有if加入 //说明if已经支持了mpls-te。后期需要在isis下开启针对te的支持,需要isis通告哪些用于特选路的信息。Ex R1有5个if全部宣告进了isis,但实际只需要有3个if通告用于te选路的链路信息,就需要在这里将if加入到traffic-eng中,来标识。

Attribut-flag //配置链路亲和属性,2的32次方(4B) 42亿

查看哪些if开启了te的功能,以及if下配置的attribute flag。
在if上开启rsvp同时为if预留带宽

如果没有指定接口的预留带宽,会默认使用接口75%的带宽作为预留带宽使用。下面这俩带宽用于te的qos。如果只指定一个接口的带宽,并没有区分流量。实际可以根据标签里的优先级不同为不同的优先级预留不同的带宽。ex:有一个ds-te,区分服务te,根据报文的优先级指定不同的带宽。percentage,通过指定百分比进行带宽的预留,rdm和mam都用于qos,只不过是不同的模型。

查看哪些if宣告进了rsvp,以及预留的带宽
看状态的命令

te的up。只有在ldp的视图下开if,ldp才会是up的

maxflow,用于ds-te,区分流的
在协议下开启对te的支持,针对哪个level。以及需要配置r-id,来标识一台设备

宣告进level-2的链路,同时开启了te的功能的情况下,才会通告这条链路的te选路信息。以上r1的配置完成。
R2的配置ios
Mpls traffic-eng tunnels //全局开启te的功能
if下 mpls traffic-eng tunnels
mpls traffic-eng attribute-flag
ip rsvp //if开启rsvp
ip rsvp bandwidth

验证if是否开启rsvp,是否预留了带宽
在isis下开启对te的支持:
Router isis xx
Mpls traffic-eng level-l/r-id

ios可以这样快速检索
Te-tunnel配置完成后,可以在ingress节点,show mpls traffice -eng topology brief,查看所有的节点信息和链路信息。
ex

显示,设备通告的link信息,接口信息,nei的ip地址,metric和attribute-flag
通过上述命令就可以判断设备通告的链路信息全不。

isis已经通告了用于te选路的信息(标灰色处)
———————————————–
2023-03-15 12:56
video 54
在配置了链路亲和属性之后,需要在tunnel下指定使用什么样的链路进行计算,如果不指定,默认使用不存在链路属性的链路进行计算。如果你的链路都存在链路属性,就会导致计算失败。
1到达5指定走tunnel,可以通过静态路由和auto
route两种方式来实现。
静态路由:就是配置静态路由,nh为tuntel-te接口
cisco的cef和fib的区别是啥(现在的设备已默认开启了ip cef(快速转发),开启ip cef后就会开启fib表项,如果不开就是进程转发 。而标签转发是基于fib的,只不过出去的时候会关联标签)
R5:
Mpls traffic-eng signalling
advertise explicit-null //通告显示空标签
自动路由的方式,是让igp可以通过tunnel接口来做选路,配置:
Tunnel if下,autoroute announce

指定te metric值的方式
1.指定tunnel的metric值,实际到达目标前缀的metric=tunnel 的metric+对端通告的前缀metric
2.绝对值,通过该tunnel到达所有prefix的metric都是设置的这个绝对值,不需要再累加对端(不一定是tunnel的端点,也可能是tunnel端点后面一台设备6.6.6.6通告的)通告的前缀metric,如下图


3.相对值,相对于igp的metric进行正负偏移。ex:之前te引用igp的metric 为40,这里设置相对值为-10,则te tunnel (经过te tunnel的路由)metric的值就为30
————————————————————
2023-03-16 12:27
Video 55

会沿着cspf算法计算的转发路径去发送pass和receive报文,这个路径就存放在explicit route里。
而record route中会追加经过设备的出接口if,以此来防环。类似bgp 的as-path和clust list 。第二个作用,用于te的frr,ex在节点保护的场景中,需要用到record route来记录nn号补的标签。

te为协议/数据的可靠性有很多方案存在的。
本节主要讲区域间的流量工程
区域内可以部署一个igp,则每台设备的te的link database是同步的。而区域一旦分割后,链路信息是不能跨区域传播的。
3类lsa本质来说就不是链路信息,而是一条路由。
跨区域部署mpls-te就会存在问题,因te是基于cspf算法来计算从源到宿的最短路径,这俩应该在同一个区域内。否则就没有到达目的的链路信息或节点信息的,无法执行spf算法。
想要跨区域建立mpls-te的tunnel,需要针对另一个区域内的设备,配置显示路径(需要在ingress节点配置完整的路径)。且显示路径里配置到达另一区域设备的指定路径类型应为松散型。(如果配置为strict模式,te tunnel肯定起不来)
在配置显示路径时,指定的 每一跳都可以指定2种方式:lossse or strict。
strict:从源到宿,必须严格按照你指定的设备一跳一跳去经过
loose:到达宿端前,你需要经过这台设备,但你到达这台设备的距离是可以做自动计算的(并不是直连的)

到达某一台设备可以通过两种方式来指定:1.指定到达设备的r-id(到达这台设备只有一条链路可达);2.到达设备的接口ip地址(有多条链路可达,此时如果指定的是r-id,就会自动进行计算)
r-id可以标识一台设备,而ip地址可以标识一条链路。
sr中同理,ex:在源和宿之间建立一条sr的lsp,也需要指定sr的tunnel需要经过哪台设备的哪条链路。可以在sr上为设备配置一个node prefix sid,通过该id来标识这台设备。同时为每一个loop if,配置prefix sid,而针对每一条if,会自动生成一个adjacent id。
即,通过node prefix sid来标识一台设备,通过adjacent id来标识一个接口。


不支持自动路由,是因为跨区域可能会造成环路的问题。自动路由是指igp会使用te的tunnel做路径的计算,如果通过跨区域的te-tunnel做了计算后,很可能出现环路。
想让流量走跨区域的te-tunnel,只能使用静态路由的方式
跨区域不支持亲和属性:通过链路的亲和属性来选择链路的,这些链路就是打了tag的链路标记,当跨区域后,是接收不到其他区域的链路信息的,也就不知道其他区域有哪些类型的链路是否符合你的要求,so无法计算。

需求:xr2-r8之间建立te-tunnel
因为是跨区域的,so,Xr2上配置显示路径,必须要经过xr1。域内可以配置strict,在指定r8需要配置为loose。Say: 到达r1后,由r1自己进行cspf算法计算如何到达r8。
配置:1.在全局下开启mpls-te(xr不需要),if下开启te;2.在if下开启rsvp-te,预留带宽;3.让igp通告用于te选路的链路信息-即在igp下开启支持te的功能。此时就可以看到用于te选路的链路信息


在igp下开启对te的支持

配置显示路径,然后在te-tunnel上应用该显示路径
Tunnel up就是正常的了
如果配置的转发路径有问题,最终会接收到pass error报文,可以根据这个进行debug。receive报文可以根据receive-error报文ts。
一般情况下,te-tunnel起不来,要查看配置,确认区域内的链路信息or节点信息全否,可以看下te-tunnel的database通告的信息是否全了
以下为链路管理,主要是针对rsvp的


Te-tunnel,在超过上行下行带宽阈值的条件下,会触发重新计算,去动态选择没有拥塞的转发路径

————————————————————-
2023-03-17 10:03
Video 56
Mpls te流量转发
1.静态路由转发


ios和地址族里为xr的配置

如图,到达G需要经过B,这就没走tunnel,而走的igp。即想要通过te-tunnel到达哪台设备,必须要手动配置才行,不配置是不会走te-tunnel的。
2.自动路由转发

需要在igp下开启autoroute的功能,开启该功能后,igp就会使用te-tunnel来进行spf算法的计算/igp会将te-tunnel看成一个if来自动计算的。但此方案只适用于本地计算,本地会将该te-tunnel看出一个if进行选路,但该接口的信息并不会通告进igp的 链路信息。如果想让接口信息通告出去,就需要配置转发连接

因为首端设备并没有将te-tunnel的信息通告出去,so其他设备不知道te-tunnel的存在。而如果将te-tunnel信息通告出去后,其他设备也是可以进行选路的。


所有经过G到达的前缀,都会自动迭代nh进te-tunnel。如果使用静态路由,想实现上图的效果,就需要在A上分别配置3条静态路由。A上会将te-tunnel看成一个接口,用这个接口来进行计算。
开启autoroute之后,只会影响目标节点后端的前缀,不会影响该tunnel前面的前缀,ex:G左面的 。只会影响igp选路后的路径。ex:te-tunnel配置为metric5,可能出现问题A-g-e metric为15,a-b-e 20,这样就存在环路问题了。但实际并不会出现该问题。
总结:igp的autoroute计算,是在igp选路后的计算,且只能针对tunnel后端的设备和前缀进行计算,而针对tunnel源到达宿端中间所经过的设备选路时不会有影响的。
Te-tunnel只有唯一的一条从源到目的的转发路径,so不存在负载,如果想实现负载,就必须在源和宿之间建立多条tunnel才行。te-tunnel之间是可以实现负载的。
从源到目的的转发路径上,tunnel和igp是不能实现负载分担的,而针对后端的前缀,tunnel和igp是可以实现负载的。
可以看 基于mpls的流量工程书中的等价负载分担
在源到宿存在多条te-tunnel并且tunnel的cost相同,就可以实现负载分担。

如图,不可能让a-b-c的te-tunnel和a-c的igp实现负载。在源到目的的转发路径上,不存在te-tunnel和igp的负载分担,但是针对尾节点后端的设备或前缀,可以实现转发路径igp和te-tunnel的负载分担。这样做的原因是为了避免环路问题。
ex:a-d,可以在igp和tunnel上实现负载,因为metric都是30

配置autoroute announce 后,默认情况下,tunnel会引用从源到目的累计igp metric作为tunnel的metric值使用。也可以设置相对值、绝对值。


如图,c-e间配置te-tunnel,则c到达e以及e后端的设备,都会迭代进te tunnel。但a上不知道c上有te tunnel的存在,转发还是会按照igp的路径来转发。
ex:A-F,A计算路径时,肯定走a-b-e-f。即便是C-e配置了一条te-tunnel,但A还不知道这条te-tunnel的存在,还是会保持之前的igp路径进行选路。
要求实现,其他igp的peer也使用te tunnel来选路,这就需要用到转发连接。
转发连接和autoroute的区别:autoroute指头节点自己在选路时会使用te tunnel作为选路的的出接口,但不会吧tunnel接口的信息通过进igp,其igp peer是不知道的。而一旦配置转发连接后,头节点就会把te-tunnel接口变成一条链路信息通告进igp,else设备就可以接收到,会认为这就是一条链路,可以使用该te tunnel来进行选路。//lsp中就可以看到该te-tunnel的链路信息。
需要配置forwarding adjacency



开启转发连接后,A到达tunnel宿端后的节点/前缀,都会走tunnel了


isis通告的lsp里是把tunnel接口作为链路信息进行通告的

出接口都迭代到tunnel中。上图这个应该是头节点的,而在R1上路由的nh应该是rtc
方式3:pbr

配置完pbr后,需要将pbr绑定到入接口。pbr只对入接口生效,出接口不生效。
Mpls-te流量的保护和恢复
te-frr才是frr的鼻祖,解释了为啥早期isp会喜欢使用te

vpn也有frr:vpn路由的frr
总结:凡是路由都会存在frr的机制,只不过实现的方式不同,但基本的理论都是提前为前缀计算备份路径,并写入到fib中,这就可以保证在主路径故障的情况下进行快速的切换。
ip-frr中所包含的三种路径类型,存在主路径、次优路径和备份路径(备份路径不一定是次优路径)。
cisco的cef表,就是fib表
一个ip报文到达设备后,是经过转发层面进行转发,并不会上升到控制层面
集中式设备,控转一体。
框式设备(分布式设备:控制层面和转发层面分离),cisco的主控板rp板(负责控制层面),接口板 lc板(负责转发层面)。
如果lc板卡将所有的ip报文都交由rp板处理,不现实。为了实现快速转发,都是由lc板卡直接转发的,不需要告知rp板。So lc板就应该存在fib和lfib表项-由rib下发给lc(rp板先进行选路计算后,将表项同步给lc板。lc在后续接收到标签/ip报文后就能查自己的表项转发了。但必须要保证控制层面和转发层面的实时同步-依靠两者之间的ipc通道)。ex:lc板卡收到大量ip报文(二层已经解析为自己了,so在r之间传输的不是ip包,就是标签报文)都需要rp板处理,就会导致ipc通道被占满。
案例:配置很多acl之后,cpu的使用率非常高。because,if一个if绑定了多个acl,报文过来会逐条进行match-rp板去做。会导致ipc通道被占满,导致lc-rp板失联,然后整块lc板会重启,就这样往复。
so厂商对lc板卡内的规格有明确的要求。如:pbr,acl,路由的数目。如果超过数量限制可能出现问题。
Ip frr中因为lc板的fib表项中已经被写入了备份路径,所以可以在主路径终端后,快速将流量切换到备份路径。
现在的router,基本都是基于x86的架构(每个板卡都会有一个cpu,性能强悍,spf的重新收敛可以控制在ms级),低端的会采用arm架构

ipfrr的切换是由转发层面操作的,和igp没有关系。lc板卡在感知到端口故障后,会自动将流量切过去。igp还是会重新做一次选路,将新的转发路径再写入到fib中,此时流量会从备份路径切换回次优路径。但回切就可能会造成临时环路或lsp没建立完成的问题。因,igp先完成收敛(或者其他设备igp收敛时间差问题),就将流量切过去了,但lsp还没建立成功,导致标签报文全部丢失。
该问题可以配置延时回切(从备份路径切换到新的最优路径)来解决
直连故障的检测:bfd,efm 最后一公里以太网EFM(Ethernet in the First Mile),check efm和bfd使用上的区别?
———————————————————————————–
2023-03-18 22:17
Video 57
如果存在多条te-tunnel路径的情况下,会存在仲裁原则,最终只会计算出一条备份路径。即:备份路径不可能存在多条。
frr在igp里分为静态frr和自动frr,静态frr指通过手动的方式制定静态的备份nh,而自动frr是通过igp自动进行计算,其又分为lfa和remote lfa (针对igp路由计算无环的备份下一跳)
Ti-lfa是sr的机制,而lfa和remote-lfa是基于ldp的机制。
Remote-lfa,是计算从头节点到尾节点,有哪些设备是不经过故障链路。
ldp可以为直连、静态和igp路由分配标签;同时在ldp中标签的分配空间是每平台每标签:针对一个前缀,一个设备只分配一个标签。但有个问题,只有直连的设备才能交互标签,非直连的设备之间是不能交互标签的。所以,在标签报文的保护中,remote-lfa就需要配置remote-ldp peer(通过单播方式建立的)来实现非直连peer间标签的交换,即让R1知道R3(pq节点)为4.4.4.4/32分配的标签是啥。
lfa,只能用于直连备份nh的计算,如果是非直连,则计算不了。
Remote-lfa,可以同时保护ip流量和标签流量

Te-frr是通过rsvp-te来分配标签的,但rsvp不存在reomte rsvp nei,全是直连间建立peer关系。那假如在节点保护的情况下,向上图一样需要将流量交给非直连的设备,源端如何获取到非直连设备所分配的rsvp标签?

链路保护可以理解为直连保护,而节点保护可以理解为非直连保护。
保护类型,基本厂商都支持第二种facility backup。通过frr的机制,可以保证te流量50ms的故障切换。


如果nhop=mp设备,就正好符合链路保护;如果nnhop=plr,就满足节点保护


被保护的链路rtc-rte的链路故障,需要在plr节点(C)上为需要保护的链路建立一条备份的lsp(建立一条从c-e的备份路径)。备份路径的头节点正好是plr(C),在故障点去修复路径,而备份路径的尾节点就是mp-rte。nh和mp正好是一台设备,说明满足链路保护。
如果故障的是rte这台设备,就需要在plr上建立一条备份的te-tunnel,绕过rte到达rtg。 Nnh=mp,就满足节点保护。
节点保护是可以同时实现链路保护的。

初始正常情况下是一层标签。而当主链路故障时,te-frr是会在plr节点再封装一层标签 ,以到达保护链路的对端(RTE)。
节点保护实例

节点 保护的场景中,plr(RTC)需要知道rtg分配的标签是啥(这是内层标签,外面还是需要加一层到达rtg的备份tunnel的标签)。但两者是非直连且rsvp-te 只能直连建立nei关系。想要让rtc收到rtg分配的标签,就需要用到record route tlv(在receive报文中携带)。在每经过一台设备转发时,都会把设备的出接口ip地址和设备所分配的标签进行记录。
通过该方式可以获取到非直连设备所分配的rsvp的标签,可以实现节点保护。
————————————————————-
2023-03-19 12:57
Video 58
ip-frr的产生,是因为te-frr只支持保护隧道,不能按前缀来进行保护,只能保护通过这条隧道转发的流量(即只能保护标签报文)。具有较大的局限性。一般isp只会针对比较重要的流量,才会去部署te,通过te来保护这部分流量。但te需要通过rsvp-te来预留带宽,即便te-tunnel中没有流量转发,也会占用带宽,造成浪费。so当前isp很少部署te,反而会部署传统的ip转发或标签转发。引出了针对路由和标签流量怎么保护,出现了ip-frr。
静态frr的方式,很容易成环。你在A点指定的下一跳设备,很可能他到达目标节点需要经过A的,就起不到保护的作用。
Auto frr分为lfa和remote lfa。p空间:以故障节点为起点计算,哪些邻居不需要经过故障链路可以到达。扩展p空间:再以p空间的设备为节点,计算其到达哪些邻居是可以不经过故障链路可以到达的。q空间:以lsp的尾节点为根,计算有哪些设备可以不经过故障链路到达的。然后计算p和q空间的交集。后续让头节点(plr)和pq节点之间建立remote ldp,目的是获取pq节点通告的ldp的标签。

如果是ip报文,就不需要在R1和pq节点(R3)上建立remote ldp(这种方式保护的是标签流量,r1封装的内层标签是r3为r4分配的标签,外层标签为到达r3的标签),只需要封装到达r3 的label就行。
Ti-lfa,主要应用于segment routing,可以涵盖100%拓扑。其同时具备lfa和remote-lfa的功能。不同的厂商实现不一样,但一般厂商都会实现三种场景的ti-lfa。如zero segment 就是0段的ti-lfa,就是计算直连的备份下一跳,功能=lfa

1段的ti-lfa,在没有直连备份nh时,计算非直连的备份下一跳。=remote lfa,但是需要存在pq节点。如果不存在pq节点,就使用第三种方案,two segment ti-lfa,会有三层标签。
Sr-be(best effort),类似于ldp功能的基本sr。sr-te,sr的te针对te部分,sr如何去实现(可以基于mpls-te展开学习)

节点保护同时具有路径保护的能力

使用主备隧道解决方案(建立两条头节点-宿节点的tunnel,在头节点发现故障就能进行切换),但该方案如果故障节点不是头节点就不能发现故障,是不能保证50ms的故障切换,就需要使用frr。主备tunnel存在于头节点

当rta上创建了2条到达rte的tunnel。当故障发生在RTA(头节点上),rta可以快速感知,并将流量切换到备份tunnel。但如果故障发生在如图的rtb上,由于这条链路不是和rta直连的,所以rta是感知不到其故障的,只能依赖rtb告知rta这条link已经出现故障。rtb通过通告pass error报文来通告故障(chekck为何不是receive error?),然后rta再做一个切换。(针对头节点非直连的链路故障,需要下游设备向上发送pass error报文)。
另一种方式是通过igp来实现,rtb-rtd之间链路down后,igp也会收敛,RTA通过igp也能感知链路down,igp就会切换,te就会跟着一块切换。所以在te上存在两种机制:1.通过igp;2.通过rsvp报文来实现。但最终头节点信任的是rsvp 的passe rror报文通告,而并不信任igp的通告。

参考华为ne5000e手册(核心网骨干路由器)

Nh=mp说明可以形成链路保护。Nnh=mp说明可以形成节点保护


te-frr的两种保护机制
One-to-one backup 模式,从头节点-尾节点所经过的所有设备,都认为自己可能是plr,会自动计算备份路径,来保护下游的link或节点。而在第一种,灵活的备份模式下,需要手工去建立备份隧道。
cisco使用的是第一种方式one to one backup

B设备会成为一台plr设备,其需要保护链路的话,b-c之间会建立备份隧道 (绕行f),目标就是保护b-c之间的直连链路,提供链路保护。b-d之间还可以建立隧道,提供节点保护。通过该方式可以同时提供链路保护和节点保护。如果已经可以提供节点保护了,就不再需要为了提供链路保护再建立一条隧道,建议的是建立一条节点保护的隧道。但针对链路保护和节点保护,其性质是不一样的。

上图的备份隧道可以提供节点保护,正常走主路径,就是标签交换。
走备份的隧道,此时就需要再加1层标签,通过外层标签穿越备份隧道。
rsvp和ldp一样,只会把其标签通告给其直连邻居-receive报文也是一跳一跳来传递的(属于rsvp报文),b如何获取d分配的rsvp标签?在ldp里,可以通过remote ldp来建立元朝的ldp nei。但rsvp并没有远程的nei,如果获取不到标签就只能实现链路保护,而无法实现节点保护。该问题可以通过rsvp自带的route record来解决:在每经过一台设备,就把设备的出接口ip地址记录下来,放到列表里一跳跳去传递。防环。另可以记录标签,ex:rte向rta回复receive报文是,可以在receive报文里也携带root record tlv,同时记录rte的出接口ip和分配的标签;逐上游设备类似行为。Rsvp-te解决标签传递问题比remote-ldp更巧妙。
Ipv4报文的头部长度20B-60B,可以携带option,每个option长度4B,有一个option就叫做route record,就可以在ip转发时记录每经过一台设备的出接口的ip地址-但该功能在ip报文里用的较少。Ipv4的option很多,ex:md5加密、告警。

标签记录(route record)的flag,也是需要在session attribute里来置位,告知我的下游设备我支持标签记录功能。

每台设备都会把自己看成是plr设备,自动计算到达mp的备份隧道,这些信息是通过pass报文来获取的

华为可以支持这俩

A如何快速感知到这个link down? 方案1.通过b给a回复一个pass error报文,提示链路故障。(为什么不是receive error?check)如果a知道主路径链路故障,他就会撤销这条路径并重新计算,就会导致流量中断,如何让a知道b上有备份隧道,让a继续使用隧道转发?需要通过rsvp报文来实现,报文中有一个session attribute tlv,通过flag位的方式来标识是支持节点保护还是链路保护,告知下游设备,我上游设备是支持frr的功能,此时如果在下游设备上配置了备份隧道,一旦被保护的链路down后,就会向上游恢复pass error(包含告知上游设备,我现在的备份tunnel是正常的),上游设备在收到后,就知道我现在的主隧道还是正常的,可以继续往主隧道转发流量,就会避免主隧道的重新建立
看Mpls-te 第四章 rsvp


第二个图的设备,表示是支持frr和标签记录的

链路保护举例:P244


主要通过 fast re-route back infor来告知上游设备,tunnel已经被激活,这样头节点就不需要把主路径撤销、重新计算,继续按照原路径转发就行。nh会通过备份隧道的进行转发。
———————————————————————–
2023-03-19 22:44
Video 59
Lab

需求:1.r1-r4 区域内的tunnel;2.r1-R7区域间的tunnel
配置完成后,习惯性检查通告的链路信息或节点信息
Show mpls traffic-eng topology

Forwarding-adj 转发连接不需要配置
Explicit-path xx下
Index 1 next-add //第一跳
Index 2 next-add //第二跳
会自动按照这个路径去一跳一跳向下走。不敲index,也会自动逐跳向下走
Tunnel if下,path-option index dynamic/explict,针对该tunnel使用显示路径or自动计算。
——————————————————————-
2023-03-20 12:52
Video60
继续lab
如果cspf/显示路径计算不出来,会导致pass报文发送不出来。

xr上把接口宣告进rsvp,但不指定带宽的话,预留的带宽就为0,导致tunnel起不来。ios会默认使用接口带宽的75%
在头结点,没有开启fast re-route功能,在其发送的pass报文中,就不会将session attribut tlv中的保护protect位的flag位置位。

Te if下,提供节点保护


Ping interval 控制发报的时间,华为是-m

R2上发现主路径故障,会向r1发送的pass error 报文中的error tlv中告知其tunnel 存在本地修复,就不会影响r1的tunnel隧道。正切会有50ms的丢包,而回切是有个mbb的机制,不会有回包

check一下路径
————————————————————————–
2023-03-20 22:08
Video 61
现在te frr的价值大部分已经被ip frr取代。只剩下可以保留带宽和指定显示路径。
sr是用于替代ldp和te的技术,现在都是部署sr+evpn。evpn主要用于替代二层vpn



Bcakup lsp相当于从源到宿建立了一主一备两条lsp,一旦源节点感知到主lsp down,就会把流量切换到备份的lsp上。
frr并不是用来保护,端到端的完整的lsp。而是用来保护其中的节点和链路。 ex bcakup lsp场景中:2-3间的链路down,因为和1非直连,1是无法直接感知的,可以通过:1.igp收敛后感知;2.rsvp,2会向1发送pass error报文,1知道主链路/节点有故障,进行快速切换,将主lsp切换到备lsp上。
而如果拓扑规模更大,一台较远的设备上link down了,一跳跳发送pass error报文给远端,时间就不可控,不能保证50ms内的故障切换,此时需要用到frr。
头节点在同时接收到igp和rsvp上送的故障信息,只信任rsvp通告的。只有接收到rsvp的pass error报文才会进行一个切换,

现在2-4-3建立lsp,用于保护2-3间的链路,如果该链路故障,2检测到会向1发送pass error报文,会告知1其我可以提供链路保护,即在pass error报文中有一个flag 位,通告该flag位告知头节点下游设备可以提供保护功能。1上,就不会把lsp从主切换到备,继续沿着主路径转发流量,到达2时,会重新把1的流量封装,2-4-3到达3.

保护节点3-节点保护。
路径保护

路径保护,是保护一条完整的lsp。利用备份隧道来保护主隧道。称为backup lsp。而frr生成的lsp称为bybass lsp。

还有一种模式称为备份隧道(就是热备和冷备)。Hot-standby模式会提前计算好备份的隧道,提前写到转发表项中。而备份隧道:指并没有提前计算备份隧道,当主隧道down后临时计算,再去创建备份隧道切换过去,切换时间较长。

切回时存在mbb的机制

这里是通rsvp的信令来实现切换。如果先收到了igp的链路通告,也不会直接切换,还是需要等待rsvp信令通告链路或节点故障后才会切换。

上述为ios的配置命令:使用loop0接口的地址作为tunnel 1口的地址来用。创建优先级和保持优先级,7是最低的。1000单位为KB。最后两条为计算从源到目的的转发路径。
te里只会存在一条路径。
Option 可以选择dynamic/显示路径,指定你需要经过的路径,可以指定通过设备接口的IP地址或设备的router-id-这里称为te-id(sr中称为node-id,表示链路的id为adjacent id)。
最后一行命令,针对10的这条路径通过显示路径的方式指定备份路径。


此图,需要在xr1上配置两条路径

保护的是tunnel id为1 的隧道
cisco和华为都将te tunnel看成一个if/逻辑接口。但爱立信、Juniper是将tunnel看成了一条lsp。虽然厂商的想法不同,但是功能时一样的。
Juniper是将所有类型的路由,lsp都放到一张表中,是通过inet的方式进行区分。
第三章 快速重路由

要将frr(bypass)和backup区分开。frr是用于保护转发路径上某一个链路或节点故障的情况下,进行的保护。
cisco只支持facility backup,华为两者都支持

one to one backup也是bypass lsp。可以理解为一条bypass lsp隧道是用来保护一条主用的隧道。即主用的隧道和bypass隧道是有1:1的关系的。

Detour lsp的网络结构。
Facility backup,是一条bypass lsp可以提供多条主路隧道的备份,就说明bypass lsp和主隧道没有任何关系,如果将bypass lap的标签给主隧道设备,其无法识别,所以需要两层标签。




上图中的旁路隧道即为bypass隧道。


为何facility 的bypass lso可以提供一对多的保护?因为只要知道nh以及nnh通告的主路径标签,就可以实现1对多的保护(再多压入一层标签)

Detour lsp是1:1的。在此场景中,除了端点外,每个节点都可以作为plr,并且计算自己到达nh和nnh的lsp-自动生成的(在facility 里,针对plr创建的节点保护bypass lsp和链路保护 bypass lsp都需要手动建立),建立完成后默认把detour lsp和主lsp进行关联。把这些隧道全部附着在主路径上面,主路径收到detour lsp的标签后,也会直接转换成主路径的标签。
Detour lsp只需要一层标签,因detour lsp和主lsp是有关联关系的,通过这种关联关系,主路径上的设备可以分析和处理detour lsp所分配的标签的。收到一个标签,会自动转换成主路径的标签。该方式虽然减少人工配置,但会消耗更多的设备资源。每一条detour lsp都需要和主路径进行关联,无法进行复用。
而facility到达plr后,会封装外层标签,有两层标签,外层标签用于到达bypass lsp另一个端点的标签。facility这种复用的方式更方便实现。
——————————————————————————————-
2023-03-21 22:17
Video62

1和2均为故障检测


备份隧道的建立可以使用显示路径或者dynamic两种方式,主备路径是完全分开的。




se,带宽共享,更方便实现隧道的mbb机制

cisco只支持se

右侧为使能te的功能命令。

上图应该都是在R2上执行的命令,只有tracert是在R1上
Show mpls traffic-eng fast-reroute database是用在plr节点上,status为active说明bypass隧道已经在用了

ppp是有一个echo报文的,通过echo报文来检测端到端的状态,通过二层协议就可以实现快速检测。rsvp是没有hello报文的,在rsvp-te中得到了扩展,增加了hello报文,ms级别。

两层标签是指facility这种模式。One to one这种模式只有一层标签。


plr设备,会告知上游设备,我可以提供一个局部的保护,这样头节点就不需要把之前的隧道撤销。如果收到pass error报文,就说明主隧道上有链路故障或节点故障,正常情况下需要把路径撤销,再重新计算。如果下游设备可以提供frr的保护,就会在pass报文里告诉上游设备,我提供了保护,你不需要拆除主隧道。上游就不需要拆除主隧道,而是做重优化,重新计算一条到达目的路径的lsp。如果重新计算后的路径和当前的路径一致就没问题。如果不一致,就等待新的路径建立完成后再将流量切换到新路径上,称为mbb的机制,该过程不会丢包,因为新的路径已建立完毕。

即便先收到igp的报文,也不会去切,只有等到rsvp的pass error报文才会进行一个隧道的切换。因为igp可能会抖动,一旦抖动就会通告链路故障,如果只依靠igp就进行切换,可能会造成隧道的抖动。

主链路故障后的场景

R1收到path error,会向R2发送path tear,R2收到后,向R1发送resv tear来进行应答。
当存在链路保护时,R2感知到链路故障,向R1发送的path error中,会新增notification,告知R1,R2是支持本地具备保护的,则在R1上就不会把之前的隧道拆除,而是继续沿着现在的隧道转发流量,同时做一个重优化计算新的隧道(//比如重新计算经过的设备)。而在RT3上仍会向下游发送path报文来维护主隧道。在上图中RT3是mp节点,如果其感知到上图的链路故障,正常情况下就会下其下游发送pass tear, 但在开启frr机制后,要求上mp节点在这种情况下继续发送path报文来维护这条lsp隧道。
隧道建立完成后,周期性的发送pass和receive报文只是为了维护邻居状态,并不是维护隧道状态的。check 隧道状态是依靠hello报文维护的?





如果在一个plr上既有节点保护又有链路保护,则节点保护生效。
本质就是在属性里增加一个recording的功能,就会进行标签的记录了。都是通过receive报文来通告标签的。

路径保护就是backup lsp,用来保护整条主lsp的。如果主的lsp的路径上有某些节点故障或链路故障,只有当pass error报文到达头节点后,头节点才会进行切换,so切换时间较长。链路保护是一种局部的保护方式。
在实际使用中,是将backup lsp和frr同时开启,因为这俩不冲突。

Mpls-te的高级特效


优先级默认都是7。类比于ad值,越小越优

软抢占就是一种mbb


抢战时就需要看R0发送的path报文的创建优先级和tunnel2的保持优先级进行比较。

Tunnel2会被硬拆除,然后R2重新计算再转发流量。

资源抢占发生在R1的出接口上,其带宽不够用。R1向R2发送一个抢占置位的receive报文,告知R2我要抢你的带宽,你马上为你tunnel2的流量计算条新的路径,R2计算完,流量走R3后,有R2向R1发送path tear报文,主动将原隧道拆除。R1向R4发送path tear,拆除隧道释放带宽,然后R0的tunnel1再重新建立。
隧道重优化

事件驱动重优化:通过下游给我通告的日志,来自动触发重优化的过程。重优化就可能遇到在同一个隧道上带宽不够用的问题。而针对同一个隧道的带宽抢占,需要用到share explict-显示共享(se模式)

通过5元组的方式来判断需要重新建立的多个pass报文是不是来源于同一个隧道。源地址和目标地址来自同一个同一个隧道的话,4元组不会发生变化,而lsp id可能会变。在重优化时,建立新的路径时,lsp id必然就会变。但即便lsp id不同(该项可以忽略),但其他四元组相同,也会认为是同一条隧道。
在共享带宽 se里,通过5元组的方式来标识同一个隧道。

5元组的包含在上述两个tlv中

上图35m的需求增长为80M的。由于R2上只有100M的出口带宽,之前已经用了35M,现在还需要分配80M。R2就会看收到的pass报文中标识的5元组和之前tunnel的五元组是否一致,如果一致说明来自同一个源节点,就可以实现带宽共享。(忽略lsp id,因为肯定不同)。直接将之前预留的35M改为80m来建立lsp。当lsp建立完成后,再把流量切换到新的lsp上即可。此处存在带宽抢占,来自同一个隧道的抢占-本质就是带宽的共享。

逐流的方式是针对dip进行hash,然后hash到不同的接口实现一个负载分担。非等价负载分担,eigrp可以实现,存在一个系数,通过系数乘以fd的方式进行一个计算,如果小于该值都可以实现非等价负载的。其他路由协议不支持非等价负载分担(bgp也可以实现非等价负载分担,可以根据出口的带宽实现非等价,高带宽多转发,低带宽少转发)

红色注释1:每段链路的cost均为10,上图意思为igp和te-tunnel之间是不能实现负载分担的。配置tunnel之前是igp负载,然后配置tunnel后,要优选通过tunnel到达4,针对尾端设备,te-tunnel和igp是不能实现负载的。
在1上创建两条tunnel,1个走2,1个走3,这两条tunnel到达同一个端点,可以实现负载。
4后面存在节点5,在1上通过te tunnel到达5和1通过igp到达5 的cost相同,也能实现负载。
到达te端点是不能存在te和igp的负载的,如果负载可能造成环路。
非等价负载分担只能在多条te-tunnel之间实现。


动态调整接口上的保留带宽

t0/1/2/3/4均为24小时

带宽大,就往大调;带宽小,九往小调。根据转发路径的带宽拥塞程度进行动态的调整。




p-p之间部署mpls-te,而p-pe之间部署的是ldp
方案1.pe节点会封装vpn+ldp两层标签。核心网内两端p节点之前部署的是te,他接收到ldp后有两种方案:1.直接把ldp的标签转换为te的标签再进行转发,这种场景就是两层标签;2.在ldp的标签基础上再增加te的标签,变化为3层标签。上图采用的是方案2.这个方案就需要在两个p之间创建remote-ldp,因为在左侧的p节点上,会收到左侧pe发送的ldp标签,p节点需要做swap操作的,需要将ldp swap 为一个ldp,并不是把ldp swap为te,如果swap为te那就是两层标签。而三层标签的解决方案中,是需要将ldp标签swap为ldp标签的-由宿端p节点通告的,但这两台p节点不是直连的,需要在两端的p节点上配置remote-ldp peer,左侧的p节点就可以获取到右侧p节点分配的ldp标签,并再上封装te-tunnel的标签。
另一种方案2.2是在te-tunnel if下开启ldp的功能(敲mpls ip),通过tunnel建立两个p节点间直连的ldp nei(//利用tunnel来创建ldp peer来传递远端分配的标签),这种方案也会产生三层标签。
上图question,需求在左侧p节点swap一层ldp的标签,需要swap为对端p节点通告的ldp 标签,就需要在两端p节点间建立remote ldp nei/te tunnel if下开启mpls的功能,目的都是为了获取远端p节点所分配的ldp的标签。
te 终
————————————————————————————–